Classify emails into ham and spam using Naive Bayes Classifier
We’ll build a simple email classifier using naive Bayes theorem. Algorithm implemented in PHP can be found here- https://github.com/varunon9/naive-bayes-classifier
A little bit introduction-
From wikipedia:
P(A | B) = P(B | A) * P(A) / P(B) where A and B are events and P(B) != 0
P(A | B) is a conditional probability: the likelihood of event A occurring given that B is true.
P(B | A) is also a conditional probability: the likelihood of event B occurring given that A is true.
P(A) and P(B) are the probabilities of observing A and B independently of each other, this is known as the marginal probability.
Now lets assume that we have few documents which are already classified as spam or ham (training set). So the problem that “is this email ham or spam” can also be stated as- What is the probability that latest email is ham or spam given that it contains following document? (Here document is some text in email). Mathematically we can have-
P(ham | bodyText) = Probability that email is ham given that it contains document- bodyText (lets say bodyText = content of email)
P(spam | bodyText) = Probability that email is spam given that it contains document- bodyText
P(ham | bodyText) = (P(ham) * P(bodyText | ham)) / P(bodyText)
P(spam | bodyText) = (P(spam) * P(bodyText | spam)) / P(bodyText)
Preparing Training set-
We must have a training data set for our classifier to work. We’ll use MySql as database to store our training set. Lets start with database schema.


We’ll be creating two tables.
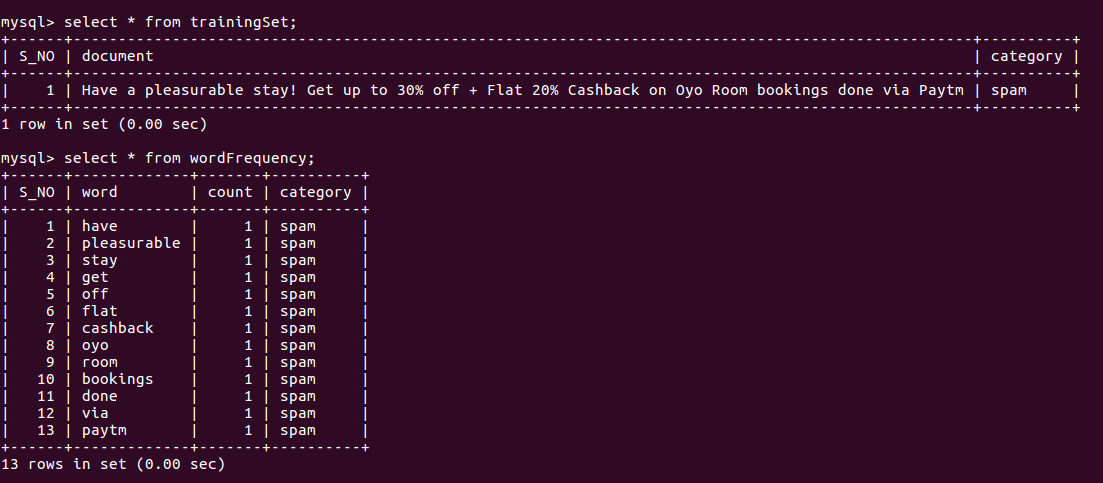
- trainingSet with columns
document(text)andcategory(varchar). This table will hold all the emails with their category i.e. ham or spam. - wordFrequency with columns
word(varchar),count(int)andcategory(varchar). This table will hold all the words seen so far along with their count and category.
Lets train our classifier with following data set. (I’ll be using https://github.com/varunon9/naive-bayes-classifier application to train our classifier).
- Have a pleasurable stay! Get up to 30% off + Flat 20% Cashback on Oyo Room bookings done via Paytm. (SPAM)
- Lets Talk Fashion! Get flat 40% Cashback on Backpacks, Watches, Perfumes, Sunglasses & more. (SPAM)
- Opportunity with Product firm for Fullstack | Backend | Frontend- Bangalore. (HAM)
- Javascript Developer, Full Stack Developer in Bangalore- Urgent Requirement. (HAM)







Implementing the Algorithm-
Our classifier will implement following pseudo code-
if (P(ham | bodyText) > P(spam | bodyText)) {
return ‘ham’;
} else {
return ‘spam’;
}
P(ham | bodyText) = (P(ham) * P(bodyText | ham)) / P(bodyText)
P(spam | bodyText) = (P(spam) * P(bodyText | spam)) / P(bodyText)
Since P(bodyText) is constant and common in both expressions, we can avoid it. Note that our goal is not to calculate the actual probability but only comparison.
P(ham) = no of documents belonging to category ham / total no of documents
P(spam) = no of documents belonging to category spam / total no of documents
To calculate the above two probabilities, we’ll use trainingSet table.
P(bodyText | spam) = P(word1 | spam) * P(word2 | spam) * …
P(bodyText | ham) = P(word1 | ham) * P(word2 | ham) * …
To calculate the above two probabilities, we’ll use wordFrequency table. Here word1, word2, word3 up to word-n are total words in bodytext.
P(word1 | spam) = count of word1 belonging to category spam / total count of words belonging to category spam.
P(word1 | ham) = count of word1 belonging to category ham / total count of words belonging to category ham.
Things to note-
What would happen if our classifier detects a new word that is not present in training data sets? In that case P(new-word | ham) or P(new-word | spam) will be 0 making all product equal to 0.
To solve this problem, we will take log on both sides. New pseudo code will be-
if (log(P(ham | bodyText)) > log(P(spam | bodyText))) {
return ‘ham’;
} else {
return ‘spam’;
}
log(P(ham | bodyText)) = log(P(ham)) + log(P(bodyText | ham))
= log(P(ham)) + log(P(word1 | ham)) + log(P(word2 | ham)) …
But wait, our problem is still not solved. If our classifier encounters a new word that is not present in our training data sets then P(new-word | category) will be 0 and log(0) is undefined. To solve this problem, we’ll use Laplace smoothing. Now we’ll have-
P(word1 | ham) = (count of word1 belonging to category ham + 1) / (total count of words belonging to ham + no of distinct words in training data sets i.e. our database)
P(word1 | spam) = (count of word1 belonging to category spam + 1) / (total count of words belonging to spam + no of distinct words in training data sets i.e. our database)
To further improve the classifier, we can tokenize the bodyText i.e content of email.
| <?php | |
| class Category { | |
| public static $HAM = 'ham'; | |
| public static $SPAM = 'spam'; | |
| } | |
| ?> |
| <?php | |
| /** | |
| * This file make connection to database using following parameters. | |
| */ | |
| $servername = "localhost"; | |
| $username = "root"; | |
| $password = "password123"; | |
| $dbname = "naiveBayes"; | |
| // Create connection | |
| $conn = mysqli_connect($servername, $username, $password, $dbname); | |
| mysqli_set_charset($conn, "utf8"); | |
| // Check connection | |
| if (mysqli_connect_errno()) { | |
| echo "Failed to connect to MySQL: " . mysqli_connect_error(); | |
| } | |
| ?> |
| <?php | |
| /** | |
| * mysql> create database naiveBayes; | |
| * mysql> use naiveBayes; | |
| * mysql> create table trainingSet (S_NO integer primary key auto_increment, document text, category varchar(255)); | |
| * mysql> create table wordFrequency (S_NO integer primary key auto_increment, word varchar(255), count integer, category varchar(255)); | |
| */ | |
| require_once('NaiveBayesClassifier.php'); | |
| $classifier = new NaiveBayesClassifier(); | |
| $spam = Category::$SPAM; | |
| $ham = Category::$HAM; | |
| $classifier -> train('Have a pleasurable stay! Get up to 30% off + Flat 20% Cashback on Oyo Room' . | |
| ' bookings done via Paytm', $spam); | |
| $classifier -> train('Lets Talk Fashion! Get flat 40% Cashback on Backpacks, Watches, Perfumes,' . | |
| ' Sunglasses & more', $spam); | |
| $classifier -> train('Opportunity with Product firm for Fullstack | Backend | Frontend- Bangalore', $ham); | |
| $classifier -> train('Javascript Developer, Fullstack Developer in Bangalore- Urgent Requirement', $ham); | |
| $category = $classifier -> classify('Scan Paytm QR Code to Pay & Win 100% Cashback'); | |
| echo $category; | |
| $category = $classifier -> classify('Re: Applying for Fullstack Developer'); | |
| echo $category; | |
| ?> |
| <?php | |
| /** | |
| * @author Varun Kumar <varunon9@gmail.com> | |
| */ | |
| require_once('Category.php'); | |
| class NaiveBayesClassifier { | |
| public function __construct() { | |
| } | |
| /** | |
| * sentence is text(document) which will be classified as ham or spam | |
| * @return category- ham/spam | |
| */ | |
| public function classify($sentence) { | |
| // extracting keywords from input text/sentence | |
| $keywordsArray = $this -> tokenize($sentence); | |
| // classifying the category | |
| $category = $this -> decide($keywordsArray); | |
| return $category; | |
| } | |
| /** | |
| * @sentence- text/document provided by user as training data | |
| * @category- category of sentence | |
| * this function will save sentence aka text/document in trainingSet table with given category | |
| * It will also update count of words (or insert new) in wordFrequency table | |
| */ | |
| public function train($sentence, $category) { | |
| $spam = Category::$SPAM; | |
| $ham = Category::$HAM; | |
| if ($category == $spam || $category == $ham) { | |
| //connecting to database | |
| require 'db_connect.php'; | |
| // inserting sentence into trainingSet with given category | |
| $sql = mysqli_query($conn, "INSERT into trainingSet (document, category) values('$sentence', '$category')"); | |
| // extracting keywords | |
| $keywordsArray = $this -> tokenize($sentence); | |
| // updating wordFrequency table | |
| foreach ($keywordsArray as $word) { | |
| // if this word is already present with given category then update count else insert | |
| $sql = mysqli_query($conn, "SELECT count(*) as total FROM wordFrequency WHERE word = '$word' and category= '$category' "); | |
| $count = mysqli_fetch_assoc($sql); | |
| if ($count['total'] == 0) { | |
| $sql = mysqli_query($conn, "INSERT into wordFrequency (word, category, count) values('$word', '$category', 1)"); | |
| } else { | |
| $sql = mysqli_query($conn, "UPDATE wordFrequency set count = count + 1 where word = '$word'"); | |
| } | |
| } | |
| //closing connection | |
| $conn -> close(); | |
| } else { | |
| throw new Exception('Unknown category. Valid categories are: $ham, $spam'); | |
| } | |
| } | |
| /** | |
| * this function takes a paragraph of text as input and returns an array of keywords. | |
| */ | |
| private function tokenize($sentence) { | |
| $stopWords = array('about','and','are','com','for','from','how', | |
| 'that','the','this', 'was','what','when','where','who','will','with','und','the','www'); | |
| //removing all the characters which ar not letters, numbers or space | |
| $sentence = preg_replace("/[^a-zA-Z 0-9]+/", "", $sentence); | |
| //converting to lowercase | |
| $sentence = strtolower($sentence); | |
| //an empty array | |
| $keywordsArray = array(); | |
| //splitting text into array of keywords | |
| //http://www.w3schools.com/php/func_string_strtok.asp | |
| $token = strtok($sentence, " "); | |
| while ($token !== false) { | |
| //excluding elements of length less than 3 | |
| if (!(strlen($token) <= 2)) { | |
| //excluding elements which are present in stopWords array | |
| //http://www.w3schools.com/php/func_array_in_array.asp | |
| if (!(in_array($token, $stopWords))) { | |
| array_push($keywordsArray, $token); | |
| } | |
| } | |
| $token = strtok(" "); | |
| } | |
| return $keywordsArray; | |
| } | |
| /** | |
| * This function takes an array of words as input and return category (spam/ham) after | |
| * applying Naive Bayes Classifier | |
| * | |
| * Naive Bayes Classifier Algorithm - | |
| * | |
| * p(spam/bodyText) = p(spam) * p(bodyText/spam) / p(bodyText); | |
| * p(ham/bodyText) = p(ham) * p(bodyText/ham) / p(bodyText); | |
| * p(bodyText) is constant so it can be ommitted | |
| * p(spam) = no of documents (sentence) belonging to category spam / total no of documents (sentence) | |
| * p(bodyText/spam) = p(word1/spam) * p(word2/spam) * .... p(wordn/spam) | |
| * Laplace smoothing for such cases is usually given by (c+1)/(N+V), | |
| * where V is the vocabulary size (total no of different words) | |
| * p(word/spam) = no of times word occur in spam / no of all words in spam | |
| * Reference: | |
| * http://stackoverflow.com/questions/9996327/using-a-naive-bayes-classifier-to-classify-tweets-some-problems | |
| * https://github.com/ttezel/bayes/blob/master/lib/naive_bayes.js | |
| */ | |
| private function decide ($keywordsArray) { | |
| $spam = Category::$SPAM; | |
| $ham = Category::$HAM; | |
| // by default assuming category to be ham | |
| $category = $ham; | |
| // making connection to database | |
| require 'db_connect.php'; | |
| $sql = mysqli_query($conn, "SELECT count(*) as total FROM trainingSet WHERE category = '$spam' "); | |
| $spamCount = mysqli_fetch_assoc($sql); | |
| $spamCount = $spamCount['total']; | |
| $sql = mysqli_query($conn, "SELECT count(*) as total FROM trainingSet WHERE category = '$ham' "); | |
| $hamCount = mysqli_fetch_assoc($sql); | |
| $hamCount = $hamCount['total']; | |
| $sql = mysqli_query($conn, "SELECT count(*) as total FROM trainingSet "); | |
| $totalCount = mysqli_fetch_assoc($sql); | |
| $totalCount = $totalCount['total']; | |
| //p(spam) | |
| $pSpam = $spamCount / $totalCount; // (no of documents classified as spam / total no of documents) | |
| //p(ham) | |
| $pHam = $hamCount / $totalCount; // (no of documents classified as ham / total no of documents) | |
| //echo $pSpam." ".$pHam; | |
| // no of distinct words (used for laplace smoothing) | |
| $sql = mysqli_query($conn, "SELECT count(*) as total FROM wordFrequency "); | |
| $distinctWords = mysqli_fetch_assoc($sql); | |
| $distinctWords = $distinctWords['total']; | |
| $bodyTextIsSpam = log($pSpam); | |
| foreach ($keywordsArray as $word) { | |
| $sql = mysqli_query($conn, "SELECT count as total FROM wordFrequency where word = '$word' and category = '$spam' "); | |
| $wordCount = mysqli_fetch_assoc($sql); | |
| $wordCount = $wordCount['total']; | |
| $bodyTextIsSpam += log(($wordCount + 1) / ($spamCount + $distinctWords)); | |
| } | |
| $bodyTextIsHam = log($pHam); | |
| foreach ($keywordsArray as $word) { | |
| $sql = mysqli_query($conn, "SELECT count as total FROM wordFrequency where word = '$word' and category = '$ham' "); | |
| $wordCount = mysqli_fetch_assoc($sql); | |
| $wordCount = $wordCount['total']; | |
| $bodyTextIsHam += log(($wordCount + 1) / ($hamCount + $distinctWords)); | |
| } | |
| if ($bodyTextIsHam >= $bodyTextIsSpam) { | |
| $category = $ham; | |
| } else { | |
| $category = $spam; | |
| } | |
| $conn -> close(); | |
| return $category; | |
| } | |
| } | |
| ?> |
Conclusion-
Naive Bayes classifier is easy to implement and provide very good result provided that our training data set is good. It can also be used to classify mood i.e. happy/sad/neutral or to classify emotions from tweets i.e. positive/negative/neutral etc. In case you find any error or problem, please create github issue at https://github.com/varunon9/naive-bayes-classifier.
https://medium.com/swlh/classify-emails-into-ham-and-spam-using-naive-bayes-classifier-ffddd7faa1ef



Comments
Post a Comment