Increase 10% Accuracy with Re-scaling Features in K-Nearest Neighbors + Python Code
Understanding the key concepts to improve performance of K-Nearest Neighbors
KNN is a Distance-Based algorithm where KNN classifies data based on proximity to K-Neighbors. Then, often we find that the features of the data we used are not at the same scale/units. An example is when we have features age and height. Obviously these two features have different units, the feature age is in year and the height is in centimeter.
This unit difference causes Distance-Based algorithms such as KNN to not perform optimally, so it is necessary to rescaling features that have different units to have same scale/units. There are many ways that can be used for rescaling features. In this story, I will discuss 3 ways of rescaling, namely Min-Max Scaling, Standard Scaling, and Robust Scaling.
- Min-Max Scaling
Min-Max Scaling uses the minimum and maximum values of a feature to rescale values within a range. Specifically, min-max calculates:
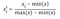

where x is the feature vector, xi is an individual element of feature x, and x’i is the rescaled element. You can use Min-Max Scaling in Scikit-Learn with MinMaxScaler() method.
2. Standard Scaling
Another rescaling method compared to Min-Max Scaling is Standard Scaling,it works by rescaling features to be approximately standard normally distributed. To achieve this, we use standardization to transform the data such that it has a mean (x̄) of 0 and a standard deviation (σ) of 1.
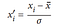

where x’i is our standardized form of xi and in Scikit-Learn you can use StandardScaler() method.
3. Robust Scaling
Last rescaling method to be discussed in this story is Robust Scaling which is commonly used to overcome the presence of outliers in our data. In this scenario, Robust Scaling rescale the feature using the median and quartile range.
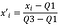

where x’i is our standardized form of xi and Q1 is first quartile, Q3 is third quartile. In Scikit-Learn, we do this using the RobustScaler() method.
After we know how rescaling features works, the next step is implemented in Python. I will use Python Scikit-Learn Library.
To follow this story, you should at least know about:
1. Basic programming in Python.
2. Pandas and Numpy libraries for data analysis tools.
3. Scikit-Learn Library for Machine Learning.
4. Jupyter Notebook.
The steps in rescaling features in KNN are as follows:
1. Load the library
2. Load the dataset
3. Sneak Peak Data
4. Standard Scaling
5. Robust Scaling
6. Min-Max Scaling
7. Tuning Hyperparameters
Dataset and Full code can be downloaded at my Github and all work is done on Jupyter Notebook.
Notes : Before rescaling, KNN model achieve around 55% in all evaluation metrics included accuracy and roc score. After Tuning Hyperparameter it performance increase to about 75%.
1Load all library that used in this story include Pandas, Numpy, and Scikit-Learn.
import pandas as pd
import numpy as npfrom sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import RobustScaler
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import GridSearchCVimport warnings
warnings.filterwarnings('ignore')
2Load dataset that will used in this story which is heart dataset that contains 303 rows and 14 columns (descripstion dataset).
df = pd.read_csv('heart.csv')3Sneak Peak Data to see which features have different units or scale with another features.
#See top 5 data
df.head()

- As you can see there are 5 numerical features that have different units. They are age, trestbps, chol, thalach, and oldpeak.
4First Rescaling uses Standard Scaling using Scikit-Learn Library StandardScaler().
#Create copy of dataset.
df_model = df.copy()#Rescaling features age, trestbps, chol, thalach, oldpeak.
scaler = StandardScaler()features = [['age', 'trestbps', 'chol', 'thalach', 'oldpeak']]
for feature in features:
df_model[feature] = scaler.fit_transform(df_model[feature])#Create KNN Object
knn = KNeighborsClassifier()#Create x and y variable
x = df_model.drop(columns=['target'])
y = df_model['target']#Split data
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=4)#Training the model
knn.fit(x_train, y_train)#Predict testing set
y_pred = knn.predict(x_test)#Check performance using accuracy
print(accuracy_score(y_test, y_pred))#Check performance using roc
roc_auc_score(y_test, y_pred)




- From the value above, we can see that the performance of knn model increase to values around 85% in accuracy and about 83% in ROC with StandardScaler!
5Next rescaling is using Robust Scaling to handle the presences of outliers in our data.
#Create copy of dataset.
df_model = df.copy()#Rescaling features age, trestbps, chol, thalach, oldpeak.
scaler = RobustScaler()features = [['age', 'trestbps', 'chol', 'thalach', 'oldpeak']]
for feature in features:
df_model[feature] = scaler.fit_transform(df_model[feature])#Create KNN Object
knn = KNeighborsClassifier()#Create x and y variable
x = df_model.drop(columns=['target'])
y = df_model['target']#Split data
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=4)#Training the model
knn.fit(x_train, y_train)#Predict testing set
y_pred = knn.predict(x_test)#Check performance using accuracy
print(accuracy_score(y_test, y_pred))#Check performance using roc
roc_auc_score(y_test, y_pred)



- With RobustScaler, the accuracy is at 83% and the ROC in 81%. Its performance is under Standard Scaler.
6The last rescaling uses Min-Max Scaling that use minimal and maximal value from features.




- With MinMax Scaler, the performance of model is highest among other rescaling methods with accuracy in 86% and ROC at 87%!
7To get optimal performance, I used GridCV to Tune Hyperparameters of my KNN model.
#List Hyperparameters to tune
leaf_size = list(range(1,50))
n_neighbors = list(range(1,30))
p=[1,2]#convert to dictionary
hyperparameters = dict(leaf_size=leaf_size, n_neighbors=n_neighbors, p=p)#Making model
clf = GridSearchCV(knn, hyperparameters, cv=10)
best_model = clf.fit(x_train,y_train)#Best Hyperparameters Value
print('Best leaf_size:', best_model.best_estimator_.get_params()['leaf_size'])
print('Best p:', best_model.best_estimator_.get_params()['p'])
print('Best n_neighbors:', best_model.best_estimator_.get_params()['n_neighbors'])#Predict testing set
y_pred = best_model.predict(x_test)#Check performance using accuracy
print(accuracy_score(y_test, y_pred))#Check performance using ROC
roc_auc_score(y_test, y_pred)





- With tuning hyperparameters + rescaling its performance is slightly the same with MinMaxScaling performance without tuning hyperparameters.
From what we have done it can be concluded that performance of distance-based algorithms such as KNN are also influenced by the scale / units of features. Therefore rescaling features is one way that can be used to improve the performance of Distance-based algorithms such as KNN.
Thank you for reading this story until the end, if there are criticisms or suggestions you can immediately comment.
https://medium.com/datadriveninvestor/increase-10-accuracy-with-re-scaling-features-in-k-nearest-neighbors-python-code-677d28032a45



Comments
Post a Comment